apache
基础学习
csdn云IDE
点图层
位置编码
ps
金仓数据库
tee
android入门
LabVIEW开发
工业物联网
核酸预约检测管理系统
西枢纽
智能制造
图书商城小程序
靶机
c++20
python实现提高博客访问量
Component
next-key lock
模型训练
2024/4/11 20:17:14
释放AI创作潜能:从大模型训练到高产力应用
文章目录 每日一句正能量前言什么是人工智能生成内容(AIGC)人工智能生成内容(AIGC)能做什么为什么要用人工智能生成内容(AIGC)创作成果用Java实现冒泡排序算法学生信息收集系统学生请假管理系统需求分析教务…

PyTorch 官方库「上新」,TorchMultimodal 助力多模态人工智能
多模态人工智能是一种新型 AI 范式,是指图像、文本、语音、视频等多种数据类型,与多种智能处理算法相结合,以期实现更高的性能。 近日,PyTorch 官方发布了一个 domain library–TorchMultimodal,用于 SoTA 多任务、多模…

【机器学习】TensorFlowLite安装和模型训练
运行环境
Linux,部分库不支持Apple芯片
做AI这部分的开发,还是强烈建议装个Linux双系统或虚拟机
这些比折腾Windows和Mac上的移植环境要轻松得多
安装依赖
sudo apt install libportaudio219.6.0-1.2
pip3 install tf-models-official2.3.0
pip3 in…

单目3D目标检测——SMOKE 环境搭建|模型训练
本文分享SMOKE最新的版本的环境搭建,以及模型训练;环境关键库版本:pytorch 1.12.0、CUDA 11.3、cudnn 8.3.2、python 3.7、DCNv2。 目录
1、docker 获取Nvidia 镜像
2、安装Conda
3、创建SMOKE环境
4、编译SMOKE环境 5、下载kitti 3D目标…

【AI大模型】训练Al大模型 (上篇)
大模型超越AI
前言
洁洁的个人主页 我就问你有没有发挥! 知行合一,志存高远。 目前所指的大模型,是“大规模深度学习模型”的简称,指具有大量参数和复杂结构的机器学习模型,可以处理大规模的数据和复杂的问题&#x…
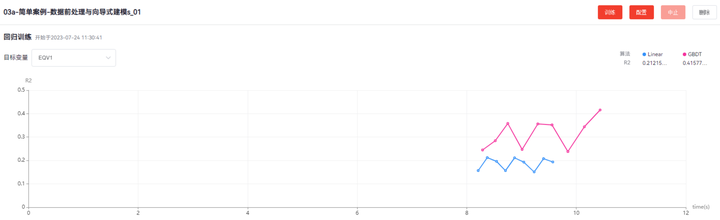
【DTEmpower案例操作教程】向导式建模
DTEmpower是由天洑软件自主研发的一款通用的智能数据建模软件,致力于帮助工程师及工科专业学生,利用工业领域中的仿真、试验、测量等各类数据进行挖掘分析,建立高质量的数据模型,实现快速设计评估、实时仿真预测、系统参数预警、设…

从传统训练到预训练和微调的训练策略
目录 前言1 使用基础模型训练手段的传统训练策略1.1 随机初始化为模型提供初始点1.2 目标函数设定是优化性能的关键 2 BERT微调策略: 适应具体任务的精妙调整2.1 利用不同的representation和分类器进行微调2.2 通过fine-tuning适应具体任务 3 T5预训练策略: 统一任务形式以提高…
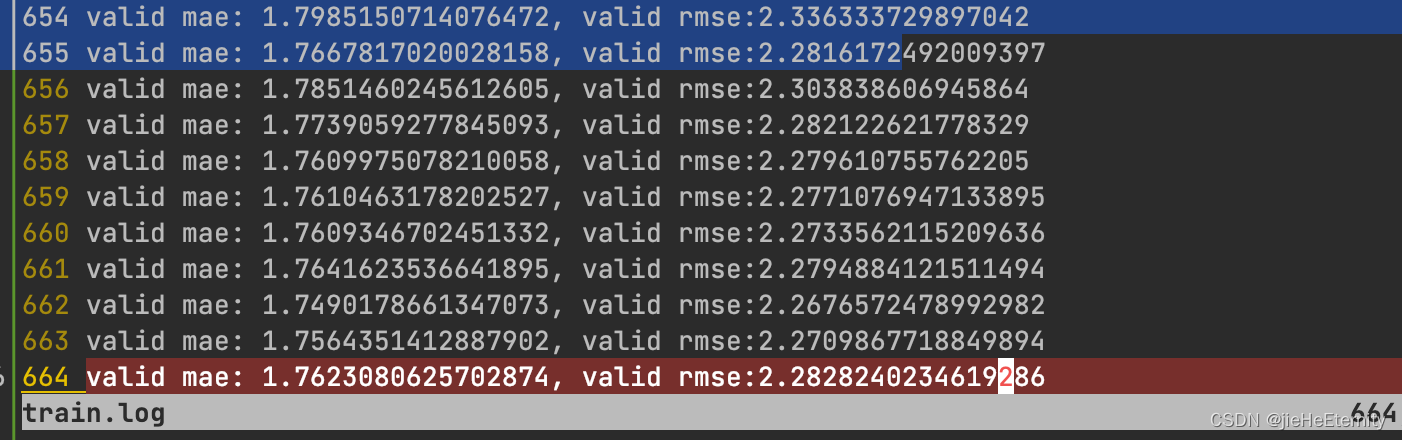
终端训练模型日志重定向
在终端中要执行模型的训练时,我们有时候既需要把模型执行的日志输出到终端展示,又想把训练日志保存到日志文件中: 假设执行的代码时trian.py
python -u train.py | tee -a ./train.log-u:这是 Python 解释器的一个选项,用于强制标…
大模型日报-20240112
重磅!OpenAI正式发布,自定义ChatGPT商店! https://mp.weixin.qq.com/s/Ic9XVFbwcR35Tcr25w28oA
OpenAI发布自定义GPT商店,开启商业模式,推出32K上下文的ChatGPT Team版本,助力学术研究、编程分析等&#x…

Meta AI | 指令回译:如何从大量无标签文档挖掘高质量大模型训练数据?
Meta AI | 指令回译:如何从大量无标签文档挖掘高质量大模型训练数据? 文章来自Meta AI,self-Alignment with Instruction Backtranslation[1]:通过指令反向翻译进行自对准。 一种从互联网大量无标签数据中挖掘高质量的指令遵循数据…
深度学习实战34-基于paddle关键信息抽取模型训练的全流程
大家好,我是微学AI,今天我给大家介绍一下深度学习实战34-基于paddle关键信息抽取模型训练的全流程,我们在文档应用场景中,存在抽取关键信息的任务,比如身份证里的姓名和地址,快递单里的姓名和联系方式等等。传统的方法需要设计模板,但是这太繁琐了,也不够强健。因此,我…
精华整理几十个Python数据科学、机器学习、深度学习、神经网络、人工智能方面的核心库以及详细使用实战案例,轻松几行代码训练自己的专有人工智能模型
精华整理几十个Python数据科学、机器学习、深度学习、神经网络、人工智能方面的核心库以及详细使用实战案例,轻松几行代码训练自己的专有人工智能模型。 机器学习 人工智能的核心,是使计算机具有智能的根本途径。机器学习专注于算法,允许机器学习而不需要编程,并在暴露于新…
【AI大模型】训练Al大模型
大模型超越AI
前言
洁洁的个人主页 我就问你有没有发挥! 知行合一,志存高远。 目前所指的大模型,是“大规模深度学习模型”的简称,指具有大量参数和复杂结构的机器学习模型,可以处理大规模的数据和复杂的问题&#x…

单目3D目标检测——MonoCon 模型训练 | 模型推理
本文分享 MonoCon 的模型训练、模型推理、可视化3D检测结果、以及可视化BEV效果。
模型原理,参考我这篇博客:【论文解读】单目3D目标检测 MonoCon(AAAI2022)_一颗小树x的博客-CSDN博客 源码地址:https://github.com/2…
【pytorch】pytorch模型可复现设置
文章目录 序言1. 可复现设置代码2. 可复现设置代码解析2.1 消除python与numpy的随机性2.2 消除torch的随机性2.3 消除DataLoader的随机性2.4 消除cuda的随机性2.5 避免pytorch使用不确定性算法2.6 使用pytorch-lightning2.7 特殊情况 序言
为了让模型在同一设备每次训练的结果…
pytorch 通用训练代码讲解(very good)
文章目录 1. 模型训练参数设置2. 保证模型可复现性3. 设置device4 初始化模型权重及加载预训练权重4.1 初始化模型权重4.2 加载预训练权重4.3 在线下载预训练权重5 k-means 聚类anchors6 多卡同步bn及并行运行7 权重指数平滑ModelEMA7.1 EMA的原理及作用7.2 EMA的实现7.2 EMA的…
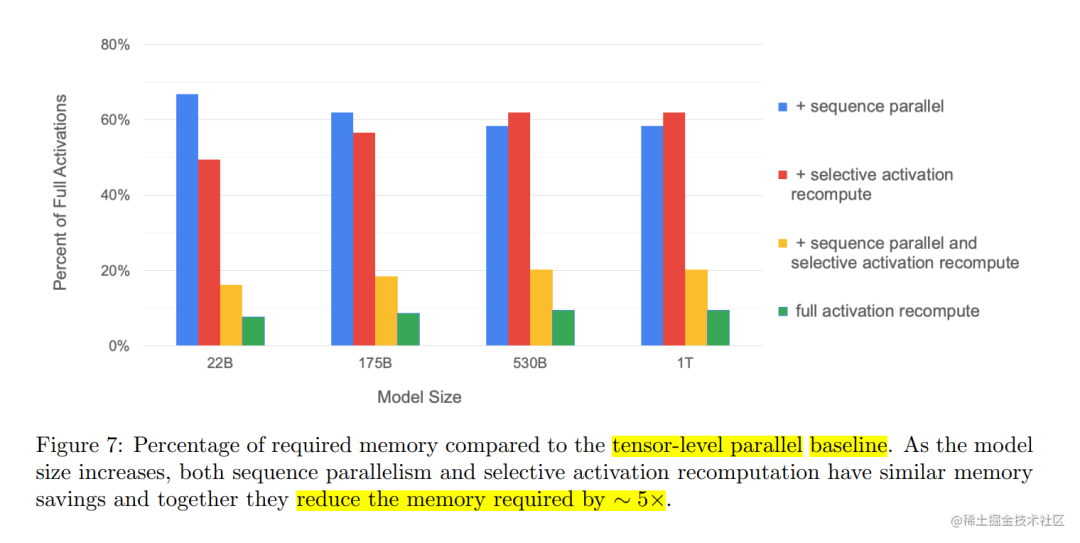
用通俗易懂的方式讲解大模型分布式训练并行技术:序列并行
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。
而利用AI集群&a…
深度学习手写字符识别:训练模型
说明
本篇博客主要是跟着B站中国计量大学杨老师的视频实战深度学习手写字符识别。 第一个深度学习实例手写字符识别
深度学习环境配置
可以参考下篇博客,网上也有很多教程,很容易搭建好深度学习的环境。 Windows11搭建GPU版本PyTorch环境详细过程
数…
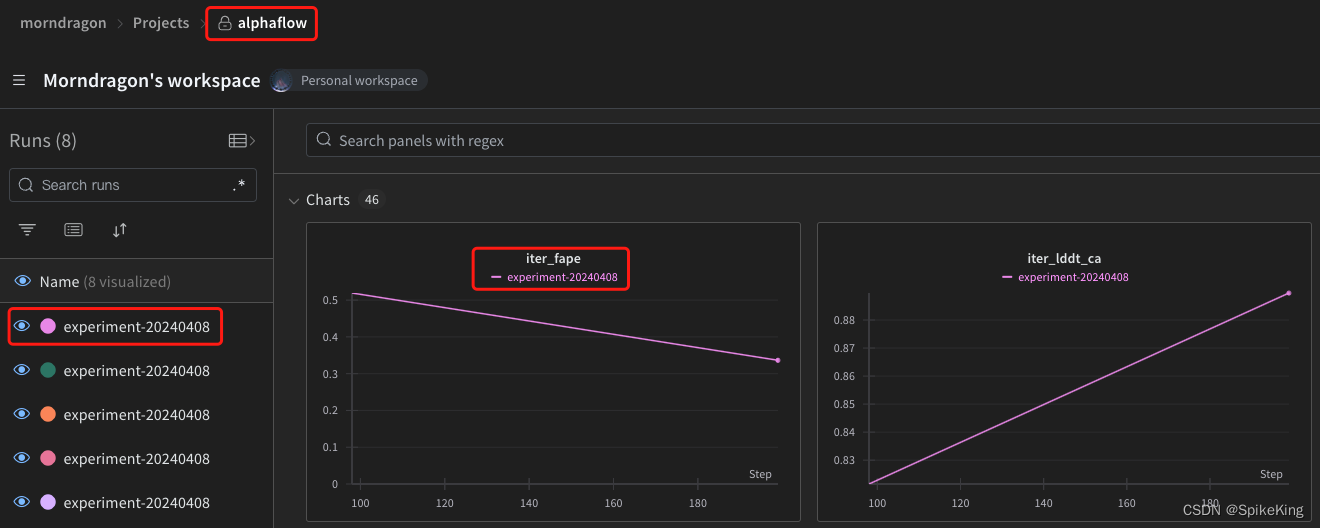
Training - 使用 WandB 配置 可视化 模型训练参数
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137529140 WandB (Weights&Biases) 是轻量级的在线模型训练可视化工具,类似于 TensorBoard,可以帮助用户跟踪…
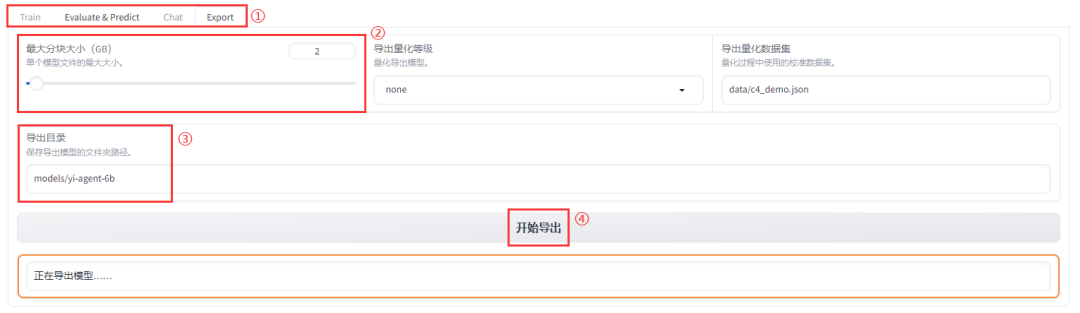
基于LLaMA Factory,单卡3小时训练专属大模型 Agent
大家好,今天给大家带来一篇 Agent 微调实战文章
Agent(智能体)是当今 LLM(大模型)应用的热门话题 [1],通过任务分解(task planning)、工具调用(tool using)和…
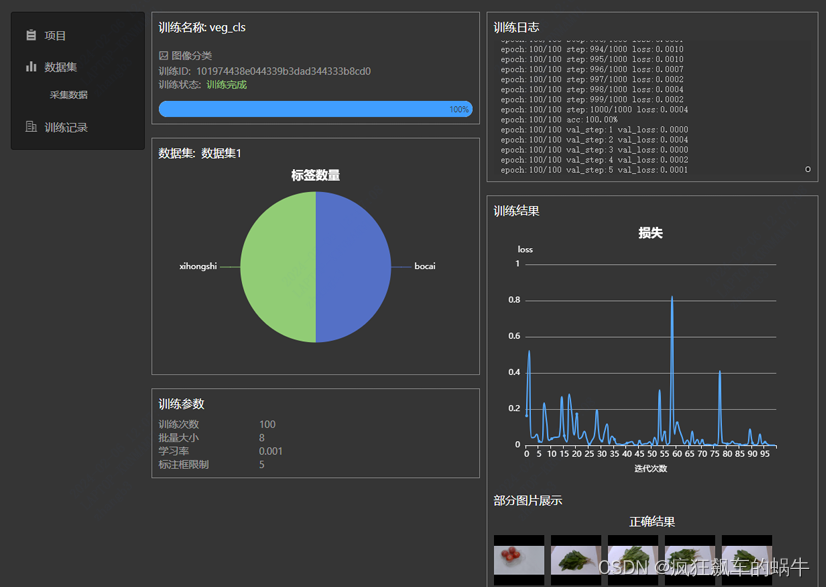
AI嵌入式K210项目(28)-在线模型训练
文章目录 前言一、平台介绍二、创建项目三、上传数据集图像分类图像检测图片上传压缩包上传 四、新建任务总结 前言
前面我们使用已经训练好的模型在K210开发板上进行了人脸识别,口罩识别,手写数字识别等实验,那么模型除了使用已经训练好的&…

如何解决“RuntimeError: CUDA Out of memory”问题
当遇到这个问题时,你可以尝试一下这些建议,按代码更改的顺序递增: 减少“batch_size” 降低精度 按照错误说的做 清除缓存 修改模型/训练 在这些选项中,如果你使用的是预训练模型,则最容易和最有可能解决问题的选项是第一个。
修改batchsize
如果你是在运行现成的代码或…
Alluxio AI 全新产品发布:无缝对接低成本对象存储 AI 训练解决方案
(2023 年 10 月 19 日,北京)Alluxio 作为一家承载各类数据驱动型工作负载的数据平台公司,现推出全新的 Alluxio Enterprise AI 高性能数据平台, 旨在满足人工智能 (AI) 和机器学习 (ML) 负载对于企业数据基础设施不断增长的需求。…
OPENCV训练模型
1.介绍
使用Cascade Classifier包括两个主要阶段:训练阶段和检测阶段。需要用到的OpenCV应用程序:opencv_createssamples, opencv_annotation, opencv_traincascade和opencv_visualisation。opencv_createssamples和opencv_traincascade自OpenCV 4.0以来被禁用,…

免费开源的多种人工智能项目,比如:训练一个模型,让人工智能玩王者荣耀
免费开源的多种人工智能项目,比如:训练一个模型,让人工智能玩王者荣耀。
全文大纲 PULSE - 该开源项目可以通过给图片增加像素点来实现去马赛克或高清化。 Depix - 给打了马赛克的文字去码。 TecoGAN - 给视频去马赛克或者进行超分辨率。 Sk…

AutoDL 使用记录
AutoDL 使用记录
1.租用新实例 创建实例需要依次选择:计费方式 → \to → 地区 → \to → GPU型号与数量 → \to → 主机 注意事项: 主机 ID:一个吉利的机号有助于炼丹成功价格:哪个便宜选哪个最高 CUDA 版本:影响…

超算互联网统一存储平台技术研究
大家好,我是来自山东省计算中心(国家超级计算济南中心)的王春晓,我从2022年开始参与超算互联网的项目,主要负责算网统一存储平台的研发,在存储基座方面也做了很多调研,最后选择了Alluxio平台&am…

植物花粉深度学习图片数据集大合集
最近收集了一波有关于植物花粉的图片数据集,可以用于相关深度学习模型的搭建,废话不多说,上数据集!!!
1、23种花粉类型805张花粉图像数据集
关于此数据:花粉种类和类型的分类是法医抱粉学、考…

百面深度学习-自然语言处理
自然语言处理
神经机器翻译模型经历了哪些主要的结构变化?分别解决了哪些问题?
神经机器翻译(Neural Machine Translation, NMT)是一种使用深度学习技术来实现自动翻译的方法。自从提出以来,NMT模型经历了几个重要的…
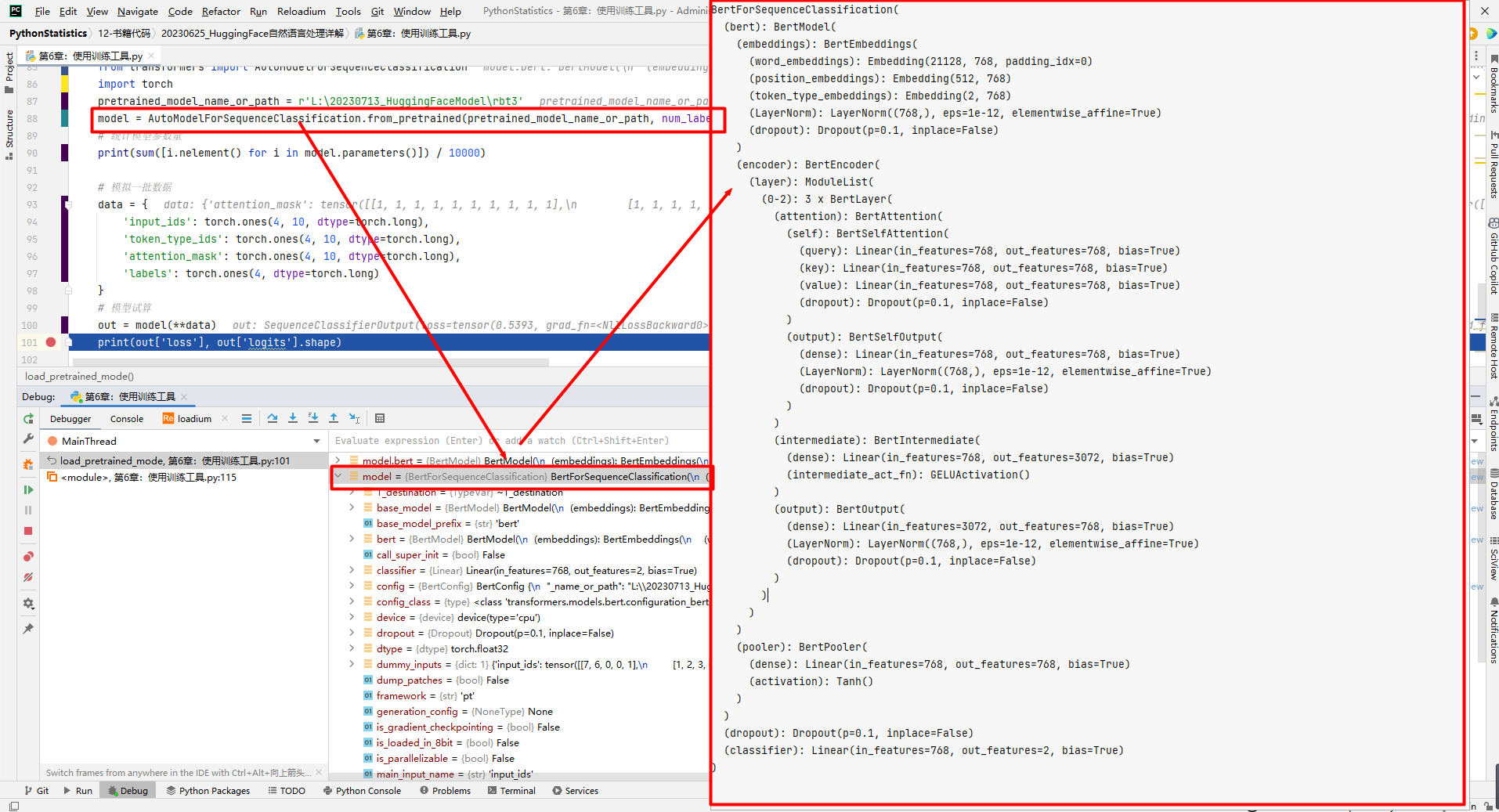

基于Python实现地标景点识别
目录 前言简介地标景点识别的背景 地标景点识别的原理卷积神经网络(CNN)的基本原理地标景点识别的工作流程 使用Python实现地标景点识别的步骤数据收集数据预处理构建卷积神经网络模型模型训练 参考文献 前言
简介 地标景点识别是一种基于计算机视觉技术…

PyTorch数据并行(DP/DDP)浅析
一直以来都是用的单机单卡训练模型,虽然很多情况下已经足够了,但总有一些情况得上分布式训练:
模型大到一张卡放不下;单张卡batch size不敢设太大,训练速度慢;当你有好几张卡,不想浪费…

突破大模型 | Alluxio助力AI大模型训练-成功案例(一)
更多详细内容可见《Alluxio助力AI大模型训练制胜宝典》
【案例一:知乎】多云缓存在知乎的探索:从UnionStore到Alluxio 作者:胡梦宇-知乎大数据基础架构开发工程师(内容转载自InfoQ) 一、背景
随着云原生技术的飞速发展ÿ…
〔024〕Stable Diffusion 之 模型训练 篇
✨ 目录 🎈 训练集准备🎈 训练集预处理🎈 数据清洗🎈 下载训练源码🎈 训练文件配置🎈 脚本运行🎈 实战测试🎈 训练集准备 声明: 该文中所涉及到的女神图片均来自于网络,仅用作技术教程演示,图片已码一般同一个训练集需要准备 20~40 张不同角度的照片,当然可…
探索人工智能 | 模型训练 使用算法和数据对机器学习模型进行参数调整和优化
前言
模型训练是指使用算法和数据对机器学习模型进行参数调整和优化的过程。模型训练一般包含以下步骤:数据收集、数据预处理、模型选择、模型训练、模型评估、超参数调优、模型部署、持续优化。 文章目录 前言数据收集数据预处理模型选择模型训练模型评估超参数调…
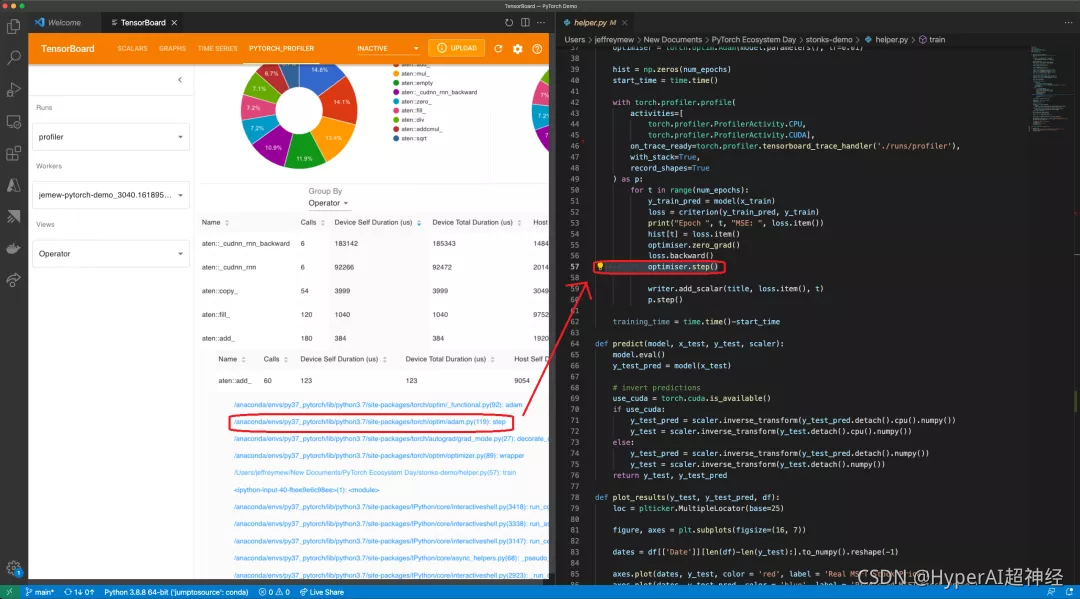
PyTorch 官方博客:PyTorch Profiler v1.9 详解
Profiler v1.9 的改进主要针对在运行时和/或内存上能耗最严重的执行步骤,同事将 GPU 和 CPU 之间的工作负载分配进行可视化。
Profiler v1.9 新增五个主要功能包括:
1、分布式训练视图: 这有助于你掌握分布式训练任务中,消耗的时…
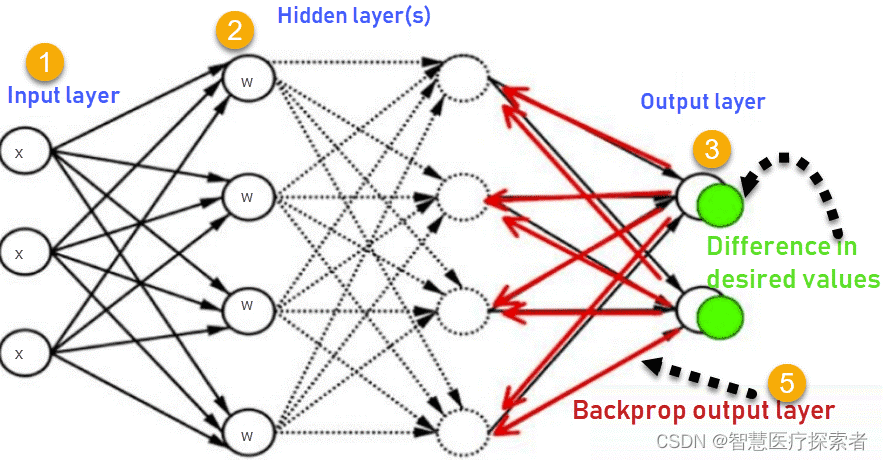
深度学习:模型训练过程中Trying to backward through the graph a second time解决方案
1 问题描述
在训练lstm网络过程中出现如下错误:
Traceback (most recent call last):File "D:\code\lstm_emotion_analyse\text_analyse.py", line 82, in <module>loss.backward()File "C:\Users\lishu\anaconda3\envs\pt2\lib\site-packag…

一种全新且灵活的 Prompt 对齐优化技术
并非所有人都熟知如何与 LLM 进行高效交流。
一种方案是,人向模型对齐。 于是有了 「Prompt工程师」这一岗位,专门撰写适配 LLM 的 Prompt,从而让模型能够更好地生成内容。
而另一种更为有效的方案则是,让模型向人对齐。 这也是…

OPPO案例 | Alluxio在DataAI湖仓一体的实践
分享嘉宾: 付庆午-OPPO数据架构组大数据架构师 在OPPO的实际应用中,我们将自研的Shuttle与Alluxio完美结合,使得整个Shuttle Service的性能得到显著提升,基本上实现了性能翻倍的效果。通过这一优化,我们成功降低了约一…
Pytorch学习笔记(模型训练)
模型训练
在同一个包下创建train.py和model.py,按照步骤先从数据处理,模型架构搭建,训练测试,统计损失,如下面代码所示
train.py
import torch.optim
import torchvision
from torch import nn
from torch.utils.da…